









Granie odpowiednimi kartami w strategii strony internetowej może mieć kluczowe znaczenie, jeśli chodzi o generowanie ruchu i przychodów. Jednym z narzędzi, które pojawia się ostatnio w rozmowach, zwłaszcza w kontekście powstanie sztucznej inteligencji, to robots.txt. Jest to prosty plik tekstowy, który pomaga wyszukiwarkom skupić się na Twoich najcenniejszych stronach. Prawidłowo używany, może poprawić wydajność indeksowania, wspierać odkrywanie treści i pomóc zmaksymalizować wydajność Twojej witryny. Przyjrzyjmy się bliżej, jak to działa.
Czym jest robots.txt?
Robots.txt to plik tekstowy, który można umieścić w głównym katalogu domeny Twojej witryny, aby informować boty wyszukiwarek, które strony powinny indeksować, a których unikać. Pomyśl o tym jak o przewodniku turystycznym, ale dla robotów indeksujących strony internetowe. Kierując roboty z dala od obszarów o niskiej wartości, można pomóc wyszukiwarkom kierować ich zasoby indeksujące na najważniejsze treści. Pozwala to wydawcy na priorytetyzację ruchu na najbardziej istotnych treściach.
Pamiętaj, że plik robots.txt całkowicie nie ukryje Twojej strony przed wyszukiwarkami i nie wszystkie z nich będą przestrzegać Twoich instrukcji. Jeśli chcesz usunąć stronę internetową z wyników wyszukiwania, użyj dyrektywy noindex i zezwól wyszukiwarkom na dostęp do strony, aby mogły zobaczyć tę instrukcję, lub zabezpiecz hasłem stronę, którą chcesz zachować w prywatności.
Jak działa plik robots.txt?
Kiedy robot sieciowy odwiedza stronę, zazwyczaj przed przeszukaniem adresów URL sprawdza plik robots.txt (lub jego zapisaną w pamięci podręcznej wersję). Dostarcza mu on instrukcji ustawionych przez Ciebie o tym, do jakich obszarów ma dostęp i do jakich nie. Plik robots.txt znajduje się w yourdomain.com/robots.txt i wygląda tak:
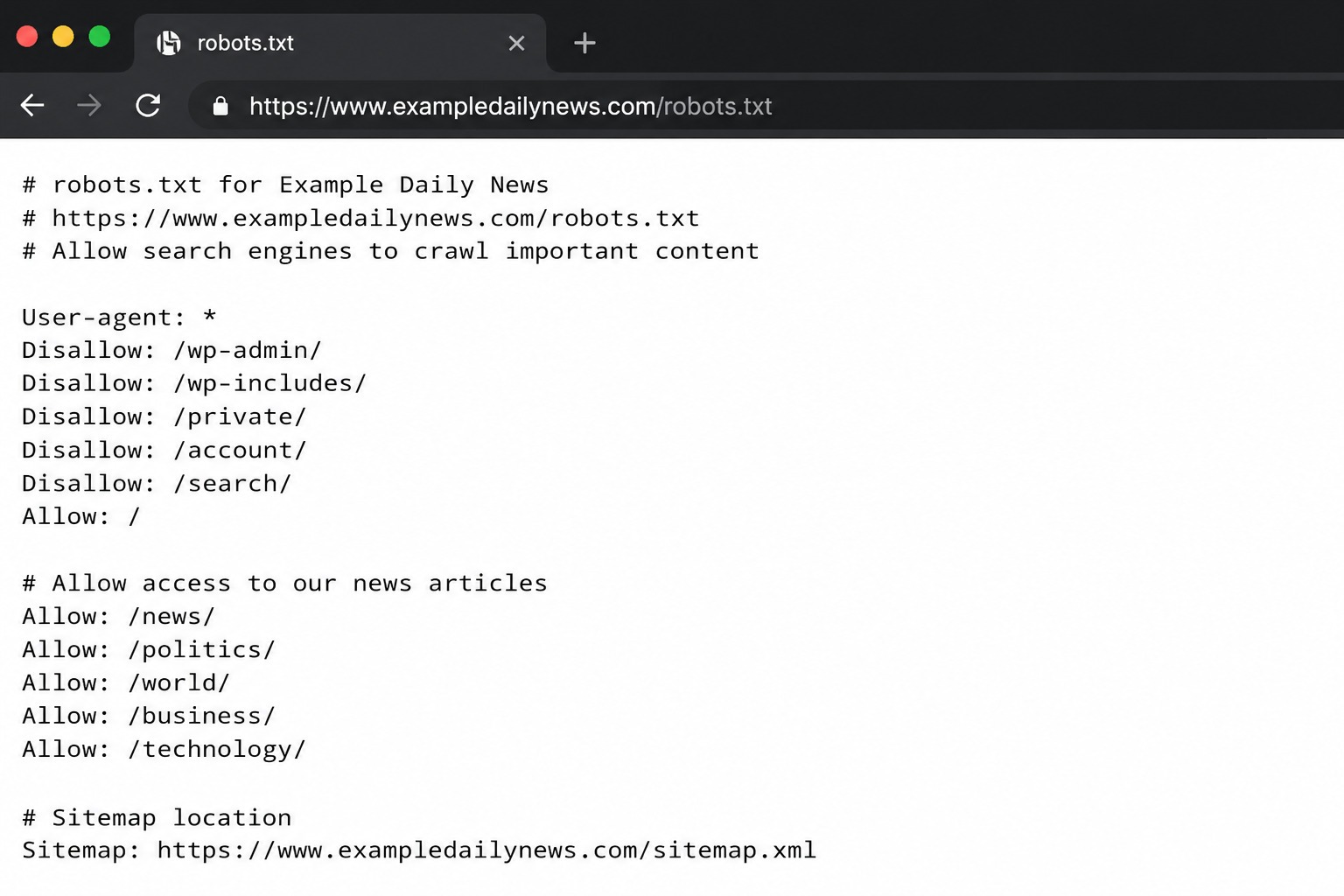
Plik robots.txt używa składni podstawowych dyrektyw, które ustalają podstawowe zasady działania botów na Twojej stronie. Są to:
-
- Agent użytkownika: Wskazuje to nazwę bota, do którego chcesz zastosować reguły (Googlebot, Applebot, Bingbot itp.). Jeśli chcesz, aby Twoje reguły dotyczyły wszystkich botów, wystarczy wpisać w to pole gwiazdkę (*) zamiast nazwy bota.
- Wyłącz Jak sama nazwa wskazuje, mówi botowi, do których stron lub plików nie wolno mu uzyskiwać dostępu. Trochę jak bramkarz w klubie nocnym, ale dla strony internetowej.
- Zezwól Ta dyrektywa informuje boty, które strony lub podkatalogi mogą przeszukiwać, nawet jeśli cały katalog ma regułę zabraniającą.
- Mapa strony Wielu wydawców umieszcza odniesienie do mapy witryny w pliku robots.txt, ułatwiając wyszukiwarkom odnajdywanie i indeksowanie ważnych stron w ich witrynach.
Na przykład, jeśli nie chcesz, aby boty indeksowały Twoją stronę “najnowsze wiadomości”, ale chcesz, aby konkretny artykuł został zaindeksowany, Twoja linia robots.txt będzie wyglądać mniej więcej tak:
User-agent: Googlebot
Disallow: /latest-news/
Zezwól: /najnowsze-wiadomosci/nazwa-artykulu/
Jak utworzyć plik robots.txt
Ułatwmy Ci pracę. Po ustaleniu stron, które chcesz zablokować przed robotami indeksującymi, możesz użyć wtyczek takich jak YoastSEO w WordPress do tworzenia i edycji pliku robots.txt.
Aby zrobić to ręcznie, musisz otworzyć prosty plik tekstowy, na przykład Notatnik, i zapisać go pod nazwą “robots.txt”. Następnie dodaj dyrektywy i prześlij plik do katalogu głównego.
Na koniec, po przesłaniu pliku, zweryfikuj go przez Google Search Console poprzez sprawdzanie raportów indeksowania i przeszukiwania oraz testowanie ważnych adresów URL za pomocą narzędzia do inspekcji adresów URL. GCS jest bardzo pomocne w śledzeniu kondycji witryny, statusu przeszukiwania i indeksowania oraz ruchu z wyszukiwarki. Niedawno Google Search Central ogłosiło, że wdrożono nowa wyszukiwarka generatywna raport wydajności IA aby śledzić swoje wysiłki GEO. Bądź na bieżąco z naszym nadchodzącym artykułem o tym, jak wykorzystać ten raport w swojej strategii!
Dlaczego plik robots.txt ma znaczenie dla wydawców?
Dla wydawców robots.txt może być użytecznym narzędziem SEO, pomagającym wyszukiwarkom efektywniej przeszukiwać Twoją witrynę, odkrywać trafne treści i poprawiać ogólną wydajność witryny. To z kolei może pomóc zmaksymalizować Twoje przychody z reklam.
Pomaga kontrolować budżet indeksowania
Wyszukiwarki przydzielają ograniczony “budżet na indeksowanie” dla każdej witryny. Wykluczając strony o niskiej wartości (takie jak strony wyników wewnętrznego wyszukiwania, strony zduplikowane lub pliki prywatne), kierujesz roboty indeksujące do swoich istotnych treści, poprawiając wydajność indeksowania i pracę witryny.
Poprawia wydajność SEO
Pliki robots.txt pomagają usprawnić indeksowanie i priorytetyzować ruch. Umożliwiają skupienie się na najcenniejszych stronach, wspierając szybsze odkrywanie treści. Odgradzają również roboty od adresów URL o niskiej wartości, takich jak strony testowe, duplikaty, obszary logowania itp.
Kontroluje skrobanie treści przez modele IA
Możesz zasygnalizować botom AI, że nie powinny uzyskiwać dostępu do określonych treści na Twojej stronie. Ta opcja daje Ci większą kontrolę nad swoimi treściami i pomaga je chronić, jeśli nie czujesz się komfortowo z LLM korzystając z niego. Jeśli jednak nie przeszkadza Ci zwiększona ekspozycja i postrzegasz narzędzia generatywnej sztucznej inteligencji jako szansę marketingową, możesz zezwolić ich robotom na dostęp do Twojej witryny według własnego uznania.
Pamiętaj, że zgodność różni się w zależności od narzędzia indeksującego i zależy od tego, czy respektuje ono plik robots.txt.
Zoptymalizuj wydajność witryny
Użycie pliku robots.txt może pomóc zredukować niepotrzebny ruch botów i obciążenie serwera. Ograniczając liczbę stron, które boty mogą przeszukiwać, serwer ma więcej zasobów dla prawdziwych odwiedzających, dzięki czemu strony ładują się szybciej. Pomaga to Twoim Core Web Vitals, ulepszając doświadczenie użytkownika.
Najlepsze praktyki dotyczące pliku robots.txt
Posiadanie pliku robots.txt nie jest obowiązkowe dla większości stron internetowych. Może jednak służyć jako dobry SEO strategia maksymalizacji budżetu indeksowania, zapobiegania przeciążeniu serwera i ochrony określonych treści. Jeśli zdecydujesz się z niego skorzystać, warto przestrzegać tych dobrych praktyk:
Nie używaj robots.txt do ukrywania swoich treści przed wyszukiwarkami.
Jeśli chcesz zachować poufność treści lub całkowicie usunąć ją z wyników wyszukiwania, użyj tagu noindex zamiast polegać na pliku robots.txt. Dzieje się tak, ponieważ Google może nadal indeksować stronę, jeśli istnieje do niej zewnętrzny link, nawet jeśli dostęp dla Googlebota jest zablokowany przez robots.txt.
Unikaj blokowania jakichkolwiek ważnych zasobów
Uważaj, aby nie blokować żadnych zasobów, takich jak CSS, JavaScript czy obrazy, których Twoja witryna potrzebuje do renderowania, ponieważ wyszukiwarki polegają na nich, aby zrozumieć układ i funkcjonalność Twoich stron.
Wykonuj regularne testy i aktualizacje pliku robots.txt.
Problemy z plikiem robots.txt mogą wpływać na Twoje SEO. Dlatego ważne jest, aby aktualizować plik wraz z tworzeniem świetnych treści i rozwojem strony. Testowanie go może pomóc upewnić się, że wszystkie dyrektywy są prawidłowo stosowane i nie zakłócają renderowania.
Robots.txt jako strategia dla wydawców: brać czy zostawić?
Robots.txt to coś więcej niż techniczny plik SEO. To przewodnik, który określa, w jaki sposób boty, roboty indeksujące i systemy SI mogą wchodzić w interakcję z treściami na Twojej stronie internetowej. Dzięki temu możesz priorytetyzować ruch na tych wartościowych stronach, które zasługują na uwagę. Dla wydawców jest to strategiczne narzędzie do zarządzania widocznością, wydajnością i dostępem do treści jak mistrz, zwłaszcza w erze, gdy wyszukiwanie zmienia się tak, jak je znamy.
Dowiedz się więcej o tym, jak zwiększyć swój ruch internetowy w tej nowej erze odkrywalności dzięki naszemu webinarowi “Przemyślane wyszukiwanie: Jak wydawcy mogą konkurować w świecie zdominowanym przez AI”. Możesz pójść o krok dalej i poprosić o Darmowy Audyt Strony. W ten sposób otrzymasz spersonalizowane rekomendacje, jak zmaksymalizować swoje przychody i wyniki w celu długoterminowego wzrostu.







