









Giocare le carte giuste nella strategia del tuo sito web può fare la differenza quando si tratta di generare traffico e entrate. Uno degli strumenti che sta emergendo nelle conversazioni di questi giorni, specialmente con il ascesa dell'IA, è robots.txt. È un semplice file di testo che aiuta i motori di ricerca a concentrarsi sulle tue pagine più preziose. Utilizzato correttamente, può migliorare l'efficienza del crawling, supportare la scoperta dei contenuti e aiutare a massimizzare le prestazioni del tuo sito. Diamo un'occhiata più approfondita a come funziona.
Cos'è robots.txt?
Robots.txt è un file di testo che può essere inserito nella directory principale del dominio del tuo sito web per indicare ai crawler dei motori di ricerca quali pagine devono scansionare e quali evitare. Pensalo come una guida di viaggio, ma per i crawler web. Allontanando i crawler da aree di scarso valore, è possibile aiutare i motori di ricerca a concentrare le proprie risorse di scansione sui contenuti più importanti. Ciò ti consente, come editore, di dare priorità al traffico verso i tuoi contenuti più pertinenti.
Tieni presente che un file robots.txt non nasconderà completamente la tua pagina dai motori di ricerca e non tutti seguiranno le tue istruzioni. Se desideri che una pagina web venga rimossa dai risultati di ricerca, utilizza una direttiva noindex e consenti ai motori di ricerca di accedere alla pagina in modo che possano vederla, oppure proteggi con password la pagina che desideri mantenere privata.
Come funziona il file robots.txt
Quando un crawler visita un sito, in genere controlla il file robots.txt (o una sua versione memorizzata nella cache) prima di eseguire lo spidering degli URL. Questo gli fornisce istruzioni da te impostate su quali aree può accedere e quali no. Il file robots.txt si trova all'indirizzo yourdomain.com/robots.txt e si presenta così:
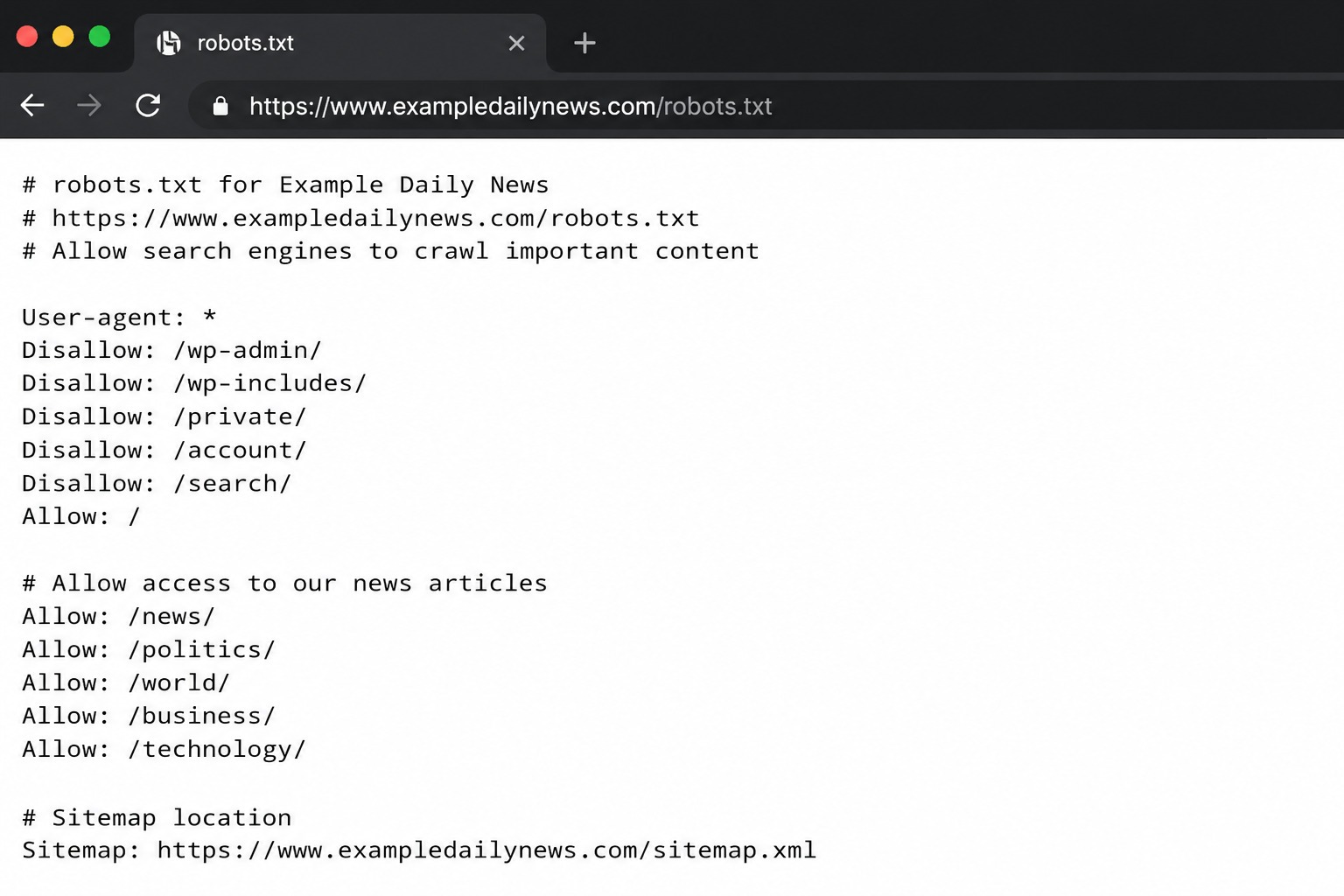
Un file robots.txt utilizza una sintassi di direttive di base che stabiliscono le regole fondamentali su come i bot devono agire sul tuo sito. Queste sono:
-
- User-agent: Ciò indica il nome del bot a cui si desidera applicare le regole (Googlebot, Applebot, Bingbot, ecc.). Se si desidera che le proprie regole si applichino a tutti i bot, è sufficiente includere un * in questo campo anziché il nome del bot.
- Non consentire: Come suggerisce il nome, dice al bot quali pagine o file non è autorizzato ad accedere. Un po' come il buttafuori di un locale notturno, ma per un sito web.
- Permettere: Questa direttiva indica ai bot quali pagine o sottodirectory possono scansionare, anche se l'intera directory ha una regola di divieto.
- Mappa del sito: Molti editori includono un riferimento alla sitemap nel loro file robots.txt, rendendo più facile per i motori di ricerca trovare e indicizzare le pagine importanti dei loro siti.
Ad esempio, se non vuoi che i bot eseguano la scansione della tua pagina "ultime notizie", ma desideri che un articolo specifico venga indicizzato, la riga nel tuo file robots.txt dovrebbe essere simile a questa:
User-agent: Googlebot
Vietare: /ultime-notizie/
Consentire: /ultime-notizie/nome-articolo/
Come creare un file robots.txt
Rendiamo le cose più facili per te. Una volta determinate le pagine che desideri bloccare dai crawler, puoi utilizzare plugin come Yoast SEO in WordPress per creare e modificare il file robots.txt.
Per farlo manualmente, dovrai aprire un semplice file di testo, come Blocco Note, e salvarlo con il nome “robots.txt”. Quindi, aggiungi le direttive e carica il file nella tua directory principale.
Infine, dopo aver caricato il file, verificarlo tramite Google Search Console controllando i rapporti sulla scansione e sull'indicizzazione e verificando gli URL più importanti tramite lo strumento di ispezione degli URL. GCS è davvero utile per tenere sotto controllo lo stato di salute del tuo sito, lo stato della scansione e dell'indicizzazione e il traffico di ricerca. Recentemente, Google Search Central ha annunciato di aver implementato un nuovo motore di ricerca performance report IA generativa per tenere traccia dei tuoi sforzi SEO. Resta sintonizzato per il nostro prossimo articolo su come utilizzare questo report nella tua strategia!
Perché il file robots.txt è importante per gli editori?
Per gli editori, il file robots.txt può rivelarsi un utile strumento SEO, aiutando i motori di ricerca a eseguire la scansione del sito in modo più efficiente, a individuare contenuti pertinenti e a migliorare le prestazioni complessive del sito. Ciò, a sua volta, può contribuire a massimizzare i ricavi pubblicitari.
Aiuta a Controllare il Budget di Scansione
I motori di ricerca allocano un “crawl budget” limitato per sito. Disabilitando le pagine di scarso valore (come risultati di ricerca interni, pagine duplicate o file privati), guidi i crawler verso i tuoi contenuti pertinenti, migliorando l'efficienza dell'indicizzazione e le prestazioni del sito.
Migliora le prestazioni SEO
I file robots.txt aiutano a migliorare l'efficienza dell'indicizzazione e a dare priorità al traffico. Aiutano a concentrare l'attenzione sulle tue pagine di maggior valore, supportando una scoperta più rapida dei tuoi contenuti. Inoltre, allontanano i crawler da URL di scarso valore come pagine di test, duplicati, aree di accesso, ecc.
Controlla lo scraping dei contenuti da parte dei modelli IA
Puoi indicare ai crawler basati sull'intelligenza artificiale di non accedere a determinati contenuti del tuo sito. Questa opzione ti offre un maggiore controllo sui tuoi contenuti e ti aiuta a proteggerli se non ti senti a tuo agio con LLM utilizzandolo. Tuttavia, se non ti dispiace l'esposizione extra e vedi gli strumenti di IA generativa come un'opportunità di branding, puoi consentire ai loro crawler sul tuo sito come ritieni opportuno.
Tieni presente che la conformità varia a seconda del crawler e dipende dal fatto che questo rispetti o meno il file robots.txt.
Ottimizzare le prestazioni del sito
L'uso del file robots.txt può aiutare a ridurre il traffico inutile generato dai bot e il carico sul server. Limitando il numero di pagine scansionate dai bot, il server avrà più risorse a disposizione per i visitatori reali, consentendo un caricamento più veloce delle pagine. Questo aiuta il tuo Core Web Vitals, migliorare l'esperienza utente.
Le migliori pratiche per l'uso di robots.txt
Avere un file robots.txt non è obbligatorio per la maggior parte dei siti web. Tuttavia, può servire come un buon SEO strategia per massimizzare il tuo crawl budget, prevenire sovraccarichi del server e proteggere determinati contenuti. Se scegli di utilizzarlo, potresti voler attenerti a queste best practice:
Non usare robots.txt per nascondere i tuoi contenuti dalle SERP
Se il tuo obiettivo è mantenere i contenuti privati o rimuoverli completamente dai risultati di ricerca, utilizza un tag noindex anziché fare affidamento su robots.txt. Questo perché Google potrebbe comunque indicizzare una pagina se esiste un link esterno ad essa, anche quando a Googlebot viene impedito di eseguirne il crawling tramite robots.txt.
Evitare di bloccare risorse importanti
Fai attenzione a non bloccare risorse come CSS, JavaScript o immagini di cui il tuo sito ha bisogno per il rendering, poiché i motori di ricerca li utilizzano per comprendere il layout e la funzionalità delle tue pagine.
Esegui test e aggiornamenti regolari del tuo file robots.txt
Problemi con il tuo robots.txt possono influire sulla tua SEO. Ecco perché è importante aggiornare il tuo file man mano che continui a creare contenuti eccezionali e il tuo sito si evolve. Testarlo può aiutarti a garantire che tutte le tue direttive vengano applicate correttamente e che non ci siano interferenze con il rendering.
Robots.txt come strategia per gli editori: prenderlo o lasciarlo?
Robots.txt è più di un semplice file tecnico di SEO. È una guida che determina come i bot, i crawler e i sistemi IA possono interagire con i contenuti del tuo sito web. Questo ti permette di dare priorità al traffico verso quelle pagine di valore che meritano i riflettori. Per gli editori, è uno strumento strategico per gestire la visibilità, le prestazioni e l'accesso ai contenuti come un campione, specialmente in un'epoca in cui la ricerca sta cambiando come la conosciamo.
Scopri di più su come aumentare il tuo traffico in questa nuova era per la scopribilità con il nostro webinar “La Ricerca Reinventata: Come gli Editori Possono Competere in un Mondo AI First”. Puoi anche fare un passo in più e richiedere un Audit del Sito Web Gratuito. In questo modo otterrai raccomandazioni personalizzate su come massimizzare le entrate e le prestazioni per una crescita a lungo termine.







