









Das Ausspielen der richtigen Karten in Ihrer Website-Strategie kann den entscheidenden Unterschied ausmachen, wenn es darum geht, Traffic und Umsatz zu generieren. Eines der Werkzeuge, das in den heutigen Gesprächen immer häufiger vorkommt, insbesondere mit dem Aufstieg der KI, ist robots.txt. Dies ist eine einfache Textdatei, die Suchmaschinen hilft, sich auf Ihre wertvollsten Seiten zu konzentrieren. Richtig angewendet kann sie die Crawleffizienz verbessern, die Inhaltsfindung unterstützen und die Leistung Ihrer Website maximieren. Werfen wir einen genaueren Blick darauf, wie sie funktioniert.
Was ist robots.txt?
Robots.txt ist eine Textdatei, die im Stammverzeichnis Ihrer Website-Domäne platziert werden kann, um Suchmaschinen-Bots mitzuteilen, welche Seiten sie crawlen und welche sie vermeiden sollen. Betrachten Sie es als Reiseführer, aber für Web-Crawler. Indem Crawler von Bereichen mit geringem Wert weggeleitet werden, können Suchmaschinen ihre Crawl-Ressourcen auf Ihre wichtigsten Inhalte konzentrieren. Dies ermöglicht es Ihnen als Publisher, den Traffic auf Ihre relevantesten Inhalte zu priorisieren.
Beachten Sie, dass eine robots.txt-Datei Ihre Seite nicht vollständig vor Suchmaschinen verbirgt und nicht alle Suchmaschinen Ihre Anweisungen befolgen werden. Wenn Sie eine Webseite aus den Suchergebnissen entfernen lassen möchten, verwenden Sie eine noindex-Direktive und erlauben Sie Suchmaschinen den Zugriff auf die Seite, damit sie diese Anweisung sehen können, oder schützen Sie die Seite, die Sie privat halten möchten, mit einem Passwort.
Wie funktioniert die robots.txt-Datei?
Wenn ein Crawler eine Website besucht, prüft er typischerweise die robots.txt-Datei (oder eine zwischengespeicherte Version davon), bevor er URLs crawlt. Dies liefert ihm Anweisungen von Ihnen darüber, welche Bereiche er aufrufen kann und welche nicht. Die robots.txt-Datei befindet sich auf deinedomain.com/robots.txt und sieht so aus:
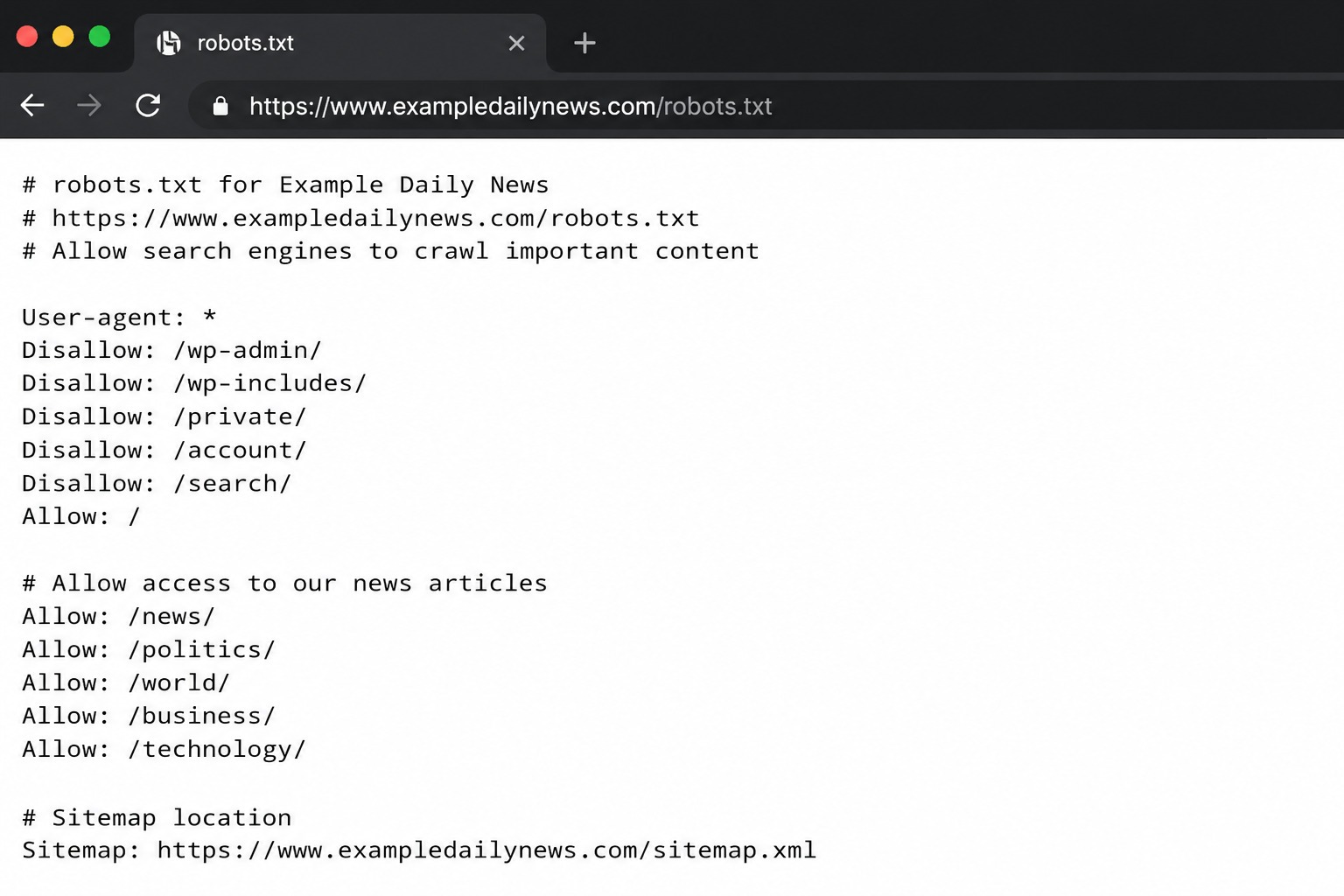
Eine robots.txt-Datei verwendet eine Syntax aus grundlegenden Direktiven, die die Grundregeln dafür festlegen, wie Bots auf Ihrer Website agieren sollen. Diese sind:
-
- User-Agent Dies gibt den Namen des Bots an, für den Sie die Regeln anwenden möchten (Googlebot, Applebot, Bingbot usw.). Wenn Ihre Regeln für alle Bots gelten sollen, müssen Sie stattdessen ein * in dieses Feld eintragen und nicht den Namen des Bots.
- Verhindern: Wie der Name schon sagt, teilt er dem Bot mit, auf welche Seiten oder Dateien er nicht zugreifen darf. So ähnlich wie ein Türsteher in einem Nachtclub, nur eben für eine Website.
- Erlauben: Diese Anweisung weist Bots an, welche Seiten oder Unterverzeichnisse sie crawlen dürfen, auch wenn das gesamte Verzeichnis eine Disallow-Regel hat.
- Sitemap: Viele Publisher fügen eine Sitemap-Referenz in ihre robots.txt-Datei ein, was es Suchmaschinen erleichtert, wichtige Seiten auf ihren Websites zu finden und zu crawlen.
Beispielweise, wenn Sie nicht möchten, dass Bots Ihre Seite “Neueste Nachrichten” crawlen, aber möchten, dass ein bestimmter Artikel indiziert wird, würde Ihre robots.txt-Zeile etwa so aussehen:
User-Agent: Googlebot
Verweigern: /latest-news/
Erlauben: /latest-news/article-name/
Wie erstelle ich eine robots.txt-Datei
Um es Ihnen einfacher zu machen. Sobald Sie die Seiten bestimmt haben, die Sie für Crawler sperren möchten, können Sie Plugins wie YoastSEO in WordPress, um Ihre robots.txt-Datei zu erstellen und zu bearbeiten.
Um es manuell zu tun, müssen Sie eine einfache Textdatei, wie z. B. Notepad, öffnen und sie unter dem Namen “robots.txt” speichern. Fügen Sie dann die Anweisungen hinzu und laden Sie die Datei in Ihr Stammverzeichnis hoch.
Abschließend, nach dem Hochladen der Datei, überprüfen Sie diese über Google Search Console indem Sie Crawl- und Indexierungsberichte prüfen und wichtige URLs mit dem URL-Inspektionstool testen. GSC ist sehr nützlich, um den Überblick über den Zustand Ihrer Website, den Crawl- und Indexierungsstatus sowie den Suchverkehr zu behalten. Kürzlich hat Google Search Central angekündigt, dass sie implementieren eine Leistungsbericht neue Suchmaschine generative KI um Ihre GEO-Bemühungen im Auge zu behalten. Bleiben Sie dran für unseren nächsten Artikel darüber, wie Sie diesen Bericht für Ihre Strategie nutzen können!
Warum robots.txt für Publisher wichtig ist
Für Publisher kann die robots.txt ein nützliches SEO-Tool sein, das Suchmaschinen hilft, Ihre Website effizienter zu durchsuchen, relevante Inhalte zu entdecken und die Gesamtleistung der Website zu verbessern. Dies kann wiederum dazu beitragen, Ihre Werbeeinnahmen zu maximieren.
Hilft bei der Steuerung des Crawl-Budgets
Suchmaschinen weisen jeder Website ein begrenztes “Crawl-Budget” zu. Indem Sie minderwertige Seiten (wie interne Suchergebnisse, doppelte Seiten oder private Dateien) nicht zulassen, leiten Sie Crawler zu Ihren relevanten Inhalten, was die Indexierungseffizienz und die Website-Leistung verbessert.
Verbessert die SEO-Leistung
Robots.txt-Dateien helfen, die Indexierungseffizienz zu verbessern und den Traffic zu priorisieren. Sie helfen dabei, den Fokus auf Ihre wertvollsten Seiten zu legen und fördern die schnellere Entdeckung Ihrer Inhalte. Außerdem halten sie Crawler von URLs mit geringem Wert fern, wie z. B. Testseiten, Duplikaten, Login-Bereichen usw.
Steuert das Scraping von Inhalten durch KI-Modelle
Sie können KI-Crawlern signalisieren, dass sie auf bestimmte Inhalte Ihrer Website nicht zugreifen sollen. Diese Option gibt Ihnen mehr Kontrolle über Ihre Inhalte und hilft, diese zu schützen, wenn Sie sich nicht wohl dabei fühlen LLMs Es zu verwenden. Wenn es Ihnen jedoch nichts ausmacht, zusätzliche Aufmerksamkeit zu erregen und generative KI-Tools als Branding-Möglichkeit betrachten, können Sie deren Crawler nach Belieben auf Ihrer Website zulassen.
Beachten Sie, dass die Einhaltung je nach Crawler variiert und davon abhängt, ob er robots.txt berücksichtigt.
Seitenleistung optimieren
Die Verwendung von robots.txt kann dazu beitragen, unnötigen Bot-Traffic und Serverauslastung zu reduzieren. Indem Sie begrenzen, wie viele Seiten Bots crawlen, hat Ihr Server mehr Ressourcen für echte Besucher, sodass Seiten schneller geladen werden. Dies hilft Ihrem Core Web Vitals, Verbesserung des Benutzererlebnisses.
Best Practices für die Verwendung von robots.txt
Eine robots.txt-Datei ist für die meisten Websites nicht unbedingt erforderlich. Sie kann jedoch als gutes SEO-Bereich Strategien zur Maximierung Ihres Crawl-Budgets, zur Vermeidung von Serverüberlastung und zum Schutz bestimmter Inhalte. Wenn Sie sich für die Nutzung entscheiden, sollten Sie sich an diese Best Practices halten:
Verwenden Sie robots.txt nicht, um Ihre Inhalte vor den Suchergebnisseiten zu verstecken
Wenn Ihr Ziel darin besteht, Inhalte privat zu halten oder sie vollständig aus den Suchergebnissen zu entfernen, verwenden Sie ein noindex-Tag, anstatt sich auf robots.txt zu verlassen. Der Grund dafür ist, dass Google eine Seite möglicherweise trotzdem indexieren kann, wenn ein externer Link dazu existiert, selbst wenn Googlebot über robots.txt daran gehindert wird, sie zu crawlen.
Wichtige Ressourcen nicht blockieren
Seien Sie vorsichtig, keine Ressourcen wie CSS, JavaScript oder Bilder zu blockieren, die Ihre Website für die Darstellung benötigt, da Suchmaschinen diese benötigen, um das Layout und die Funktionalität Ihrer Seiten zu verstehen.
Führen Sie regelmäßige Tests und Aktualisierungen Ihrer robots.txt-Datei durch.
Probleme mit Ihrer robots.txt-Datei können Ihre SEO beeinträchtigen. Deshalb ist es wichtig, Ihre Datei zu aktualisieren, während Sie weiterhin großartige Inhalte erstellen und Ihre Website sich weiterentwickelt. Das Testen kann dazu beitragen, dass alle Ihre Anweisungen korrekt angewendet werden und es keine Störungen beim Rendering gibt.
Robots.txt als Strategie für Publisher: Annahme oder Ablehnung?
Robots.txt ist mehr als eine technische SEO-Datei. Es ist eine Anleitung, die bestimmt, wie Bots, Crawler und IA-Systeme mit Inhalten auf Ihrer Website interagieren können. So können Sie den Traffic zu den wertvollen Seiten priorisieren, die im Rampenlicht stehen sollten. Für Publisher ist es ein strategisches Werkzeug, um Sichtbarkeit, Leistung und Content-Zugriff wie ein Profi zu steuern, insbesondere in einer Zeit, in der sich die Suche, wie wir sie kennen, verändert.
Erfahren Sie mehr darüber, wie Sie Ihren Traffic in diesem neuen Zeitalter der Auffindbarkeit mit unserem Webinar steigern können “Suche neu erfunden: Wie Verlage in einer KI-dominierten Welt bestehen können”. Sie können noch einen Schritt weiter gehen und eine Anforderung stellen Kostenlose Website-Analyse. Auf diese Weise erhalten Sie personalisierte Empfehlungen, wie Sie Ihren Umsatz und Ihre Leistung für langfristiges Wachstum maximieren können.







